Last Updated on December 20, 2025 by PostUpgrade
From Engines to Ecosystems: Understanding the New Search Paradigm
The new search paradigm describes the shift from traditional engines to ecosystem-based discovery systems. Modern platforms interpret context, intent, and relationships rather than relying on single queries. This change reshapes how information is retrieved, evaluated, and presented across digital environments. The transition marks a move toward continuous, intelligent, and multi-layered discovery.
Definition: AI understanding is the model’s ability to interpret meaning, structure, and conceptual boundaries in a way that enables accurate reasoning, reliable summarization, and consistent content reuse across generative discovery systems.
Why Search Is Moving From Engines to Ecosystems
The evolution of search reflects the transition from static engines to interconnected discovery ecosystems. The modern search evolution is driven by systems that analyze context, intent, and semantic relationships rather than focusing on isolated keywords. As information scales across platforms, how search is changing becomes visible through an ongoing shift in search behavior. These information discovery trends demonstrate the need for adaptive, reasoning-oriented architectures that operate effectively under complex conditions.
The Rising Complexity of Information Environments
Modern information environments function as layered and dynamic streams rather than isolated collections of documents. Users move through overlapping tasks, modalities, and interfaces, requiring systems to interpret meaning across diverse contexts. Traditional indexing structures cannot accommodate this environment because they rely on fixed organizational hierarchies and predictable ranking logic.
Three structural pressures reveal the limits of legacy engines: growing data density, continuous state change, and the expectation of immediate interpretation. Systems built on static assumptions cannot synchronize these dimensions without losing precision or timeliness. Ecosystem-based architectures address these constraints by incorporating flexible interpretive layers that adapt to contextual variation.
This progression indicates that complexity, not scale, is the primary barrier for traditional retrieval models.
Example: A page with clear conceptual boundaries and stable terminology allows AI systems to segment meaning accurately, increasing the likelihood that its high-confidence sections will appear in assistant-generated summaries.
From Query-Based Retrieval to Contextual Discovery
Search interactions have moved from isolated queries to continuous activity flows. Users transition between assistants, applications, and multimodal interfaces without explicitly formulating requests, requiring systems to infer intent from surrounding signals. This shift marks the transition from reactive retrieval to contextual discovery, where meaning emerges from accumulated cues.
The traditional model of entering a query and receiving a ranked list is being replaced by anticipatory mechanisms. Systems evaluate behavioral trajectories, semantic patterns, and temporal context to estimate emerging information needs. These processes align with ecosystem logic because distributed agents collaborate to interpret evolving user behavior.
Discovery becomes a persistent, adaptive process rather than a one-time interaction.
The Core Idea of the Ecosystem Model
The core idea behind the ecosystem model is that search functions as an adaptive network rather than a centralized engine. Instead of relying on a single index, ecosystems distribute interpretation across specialized agents that evaluate structure, meaning, and relevance in parallel. This shift aligns with recent research on generative search systems, which shows that modern discovery requires flexible, multi-stage reasoning across many computational components.
Multi-agent systems integrate their outputs through shared context, enabling layered reasoning that improves accuracy and resilience. Each agent contributes a specific capability—retrieval, synthesis, validation, or ranking—while supporting a coherent global response. This collaborative architecture replaces linear retrieval with coordinated intelligence.
In practice, ecosystems transform search from a single mechanism into a distributed, evolving discovery environment.
Principle: Content becomes more visible in AI-driven environments when its structure, definitions, and conceptual boundaries remain stable enough for models to interpret without ambiguity.
The Evolution of Search: From Direct Retrieval to Intelligent Discovery
The evolution of search demonstrates how retrieval has expanded from keyword matching to layered reasoning across complex environments. The future of search systems depends on frameworks that interpret structure, context, and semantic relationships rather than focusing solely on phrase alignment. As semantic discovery systems mature, knowledge retrieval trends show a consistent shift toward models capable of evaluating intent, structure, and emerging information needs. These developments underpin intelligent discovery systems that operate as adaptive networks rather than static tools.
Phase 1 — Keyword-Centric Engines
The earliest generation of search systems relied on direct keyword matching and index-based retrieval. These engines treated text as collections of independent terms and ranked documents chiefly through occurrence and link metrics. This model worked when the web was small and user intent could be approximated through simple patterns.
However, the approach revealed major limitations. It could not handle synonyms, ambiguity, implicit queries, or evolving user context. Keyword-centric models also assumed document stability and simple task flows, assumptions that became untenable as user behaviour diversified.
These constraints illustrate why traditional direct retrieval methods cannot fully support modern information environments.
Phase 2 — Semantic Search and Understanding
Semantic search emerged to address the shortcomings of keyword-centric retrieval. Engines incorporated embeddings, entity linking, and context modeling to process meaning rather than only term matching. This enabled systems to understand relationships between concepts and improved relevance and interpretability.
The model expanded the system’s ability to infer user intent even when queries were incomplete or vague. Semantic frameworks analyzed contextual cues, prior interactions, and domain structures to better anticipate needs. These developments align with the concept of the historical evolution of search engines, which maps how systems progressed from simple indexing to richer conceptual evaluation.
Semantic search represented the transition from surface-level matching to deeper, concept-based retrieval.
Phase 3 — Intelligent Discovery Networks
Intelligent discovery networks represent the next stage in search evolution. These systems operate through distributed agents that evaluate meaning, structure, and user behaviour in parallel. Instead of relying on a single ranked list, they coordinate multiple analytical layers to produce context-responsive outputs.
Several facets explain why ecosystems replace traditional engines:
- They integrate real-time context rather than only static relevance signals.
- They support continuous discovery across multiple interfaces and modalities.
- They allow specialized agents to perform retrieval, reasoning, validation, and synthesis.
- They adapt to changing information environments without necessitating full reindexing.
These characteristics define ecosystem-based search as a multi-layered, adaptive framework capable of reasoning over complex, evolving datasets.
In effect, intelligent discovery networks transform retrieval from a direct lookup process into a coordinated, context-aware ecosystem.

What Is a Search Ecosystem? Architecture, Logic & Interactions
A search ecosystem represents a system where discovery occurs through interconnected layers rather than a single retrieval engine. The search ecosystem model operates by distributing interpretation and action across multiple components that work in parallel. As search ecosystem trends evolve, systems increasingly rely on multi-layer information ecosystems that exchange context continuously. These connected discovery networks establish the foundation for ecosystem-centered search, where meaning and intent emerge from interactions among specialized modules.
The Core Components of a Search Ecosystem
A search ecosystem consists of structural layers that transform raw information into context-aware outputs. Each layer performs a distinct analytical function that contributes to the system’s collective reasoning. This separation of roles allows the architecture to scale across unpredictable environments. The modular structure aligns with integrated search frameworks for web ecosystems, which demonstrate how multiple interacting components support dynamic retrieval pipelines.
Table: Core Components of an Ecosystem
| Component | Function | Example Behaviors |
|---|---|---|
| Source Nodes | Provide data | Sites, feeds, structured graphs |
| Interpretive Layer | Understand signals | Large-language models, embedding networks |
| Agent Layer | Acts autonomously | Retrieval agents, summarizers |
| Output Layer | Presents results | Chat answers, cards, clustered summaries |
Each component contributes to a broader reasoning sequence. Together, they form a multi-stage system that converts heterogeneous inputs into coherent discovery outputs.
How These Layers Interact
Interaction across layers defines how ecosystems operate in real time. Data originates in source nodes and flows through interpretive models that extract structure and meaning. The agent layer then selects strategies, evaluates context, and produces candidate results. Finally, outputs are shaped into user-facing forms that vary across interfaces and tasks.
This flow — node → model → agent → user — creates an adaptive cycle that continuously integrates new signals. Ecosystems adjust parameters based on user behaviour, session history, and evolving context. Such a feedback mechanism ensures that context is retained while information moves across the pipeline.
Layer interdependence ensures that contextual signals remain active across transitions and system components.
Ecosystem Stability and Self-Regulation
Ecosystem stability emerges from continuous contextual feedback rather than fixed logic. Each layer adjusts to changes detected in upstream and downstream signals, producing a self-regulating structure. This allows the system to maintain accuracy under variation in data sources, user behaviour, and task demands.
Self-regulation relies on distributed decision-making. If one agent identifies a low-confidence signal, others adjust accordingly, preventing cascading errors common in linear retrieval architectures. Context serves as the alignment mechanism that keeps system interpretation in sync with real-world dynamics.
Through this mechanism, search ecosystems maintain coherence even as inputs, tasks and environments evolve.

From Engines to Ecosystems — The Structural Shift Explained
The shift from engines to ecosystems represents a structural change in how modern systems retrieve and interpret information. In comparing search engines vs ecosystems, the transition moves from centralized processing toward decentralized search concepts that distribute reasoning across multiple components. As distributed search models expand, systems rely increasingly on multi-agent search systems that coordinate their evaluations. These developments support autonomous discovery systems capable of adapting to unpredictable information environments.
Engines: Centralized Logic
Traditional engines operate through a centralized index that represents the authoritative map of available content. The index is updated through a linear pipeline of crawling, parsing, and ranking, which creates a rigid dependency between stages. Because the structure is unified, relevance depends on global rules that must govern the entire system at once.
This architecture restricts adaptability. Linear pipelines amplify errors from earlier stages, and updating relevance logic requires recalibrating the entire system. Engines cope well in stable environments but fail to react quickly to rapid context changes, fragmented data flows, or multimodal interaction patterns.
The limitations of centralized logic become evident when information environments demand real-time adaptation.
Ecosystems: Distributed, Multi-Agent, Self-Learning
Ecosystem-based systems replace the single index with distributed agents that interpret signals in parallel. Each agent performs a specialized analytical function—retrieval, reasoning, validation, synthesis—and collaborates through shared context. This creates an adaptive network that continuously updates as new signals appear.
Decision-making becomes decentralized. Instead of relying on a single ranking model, ecosystems evaluate relevance through multiple concurrent pathways. Research on agentic information retrieval architectures demonstrates how multi-agent models improve robustness, because each component can refine its internal logic without requiring global system restructuring. This allows ecosystems to evolve as user behavior, data sources, or task structures shift.
The result is a discovery environment that is dynamic, flexible, and capable of integrating context more deeply than linear engines.
Why Ecosystems Scale Better Than Engines
Ecosystem architectures scale more effectively because they distribute computation, interpretation, and adaptation across independent processes. Several characteristics define this advantage:
- Parallel interpretation of heterogeneous signals across many agents.
- Local decision-making that does not depend on global recalibration.
- Real-time adaptation to changes in user behavior and data distribution.
- Isolation of errors, preventing failures from spreading system-wide.
- Continuous refinement of internal models without full reindexing.
- Flexibility to support chat, cards, voice, and multimodal interfaces.
- Structural resilience under fluctuating or inconsistent information flows.
These features show why ecosystems outperform engines in environments characterized by high complexity, rapid updates, and diverse user interactions.
Human Behavior and Intent in the New Search Paradigm Framework
Human interaction with information is undergoing a structural transformation as user intent evolves across multiple contexts and devices. The user intent evolution reflects a shift from explicit queries toward patterns inferred from ongoing behavior. As search interaction patterns diversify, systems rely on context-driven discovery to interpret meaning across tasks. These changes are reinforced by conversational discovery trends that position dialogue as an active retrieval layer, enabling human-AI discovery patterns to emerge naturally across daily workflows.
Intent Becomes Layered, Not Singular
Intent in modern systems no longer appears as a single, isolated expression. Instead, it forms a layered structure composed of context snapshots that represent fragments of ongoing tasks. Systems extract these snapshots from browsing actions, application transitions, and interaction histories.
Behavioral signals play a central role in shaping this layered intent. Small cues—pauses, refinements, corrections, or page revisits—provide information that helps systems infer user goals. These signals accumulate to form a multi-dimensional model of need that evolves alongside user activity.
Layered intent allows discovery systems to maintain relevance even when queries are incomplete or never expressed directly.
The Move Toward Continuous Discovery
Search is shifting from discrete moments to continuous processes. Users now receive information without issuing explicit queries, as systems interpret context and generate anticipatory outputs. This transition reflects a deeper movement toward context-driven discovery, where meaning arises from ongoing interaction rather than isolated steps.
Continuous discovery enables systems to surface answers based on proximity to user goals. For example, task-aware models infer needs from recent actions and provide suggestions before the user formulates a request. These behaviors align with insights from conversational search behavior models, which show how retrieval shifts toward proactive, context-led interactions.
This dynamic reduces friction by merging search with real-time decision-making.
Conversation as a Search Interface
Dialogue has become a primary interface for information retrieval, transforming the search experience into an interactive exchange. Conversational discovery trends illustrate how users increasingly rely on natural language rather than formal queries. Systems interpret sequences of prompts, corrections, and clarifications to understand evolving needs.
Dialogs function as adaptive layers that incorporate reasoning, synthesis, and contextual alignment. Because each message contributes new signals, conversation becomes the new SERP, where results are generated iteratively rather than displayed in a static ranked list. Multi-turn exchanges create a structured pathway through which systems narrow ambiguity and improve relevance.
Conversational interfaces make discovery more fluid by aligning search logic with natural communication patterns.

How Intelligent Discovery Systems Work in the New Search Paradigm
Intelligent discovery systems operate by interpreting structure, meaning, and intent across dynamic information environments. Understanding how discovery systems work requires analyzing how semantic discovery systems extract context, how natural language discovery pipelines model relationships, and how adaptive discovery engines evolve with user behavior. These capabilities combine to form intelligent discovery systems that reason across multiple stages of the retrieval process.
How Systems Understand Meaning
Modern systems understand meaning by combining embeddings, contextual modeling, and multi-step reasoning. Embeddings transform words, entities, and interactions into dense vectors that capture semantic relationships. Contextual models interpret these vectors within broader task structures, allowing the system to evaluate meaning rather than surface patterns.
Multi-step reasoning enables systems to compare interpretations, validate relevance, and refine outputs. Insights from neural semantic retrieval architectures show how models integrate embeddings with contextual reasoning to produce more accurate interpretations. Meaning therefore emerges from layered analysis rather than isolated word matching.
This layered understanding forms the foundation for adaptive discovery.
Dynamic Retrieval vs Static Indexing
Retrieval mechanisms differ significantly between traditional engines and ecosystem-based systems. Engines depend on a static index, where documents are pre-ranked according to fixed rules. Ecosystems operate through dynamic retrieval, where relevance is determined in real time based on context, intent, and ongoing interaction history.
Dynamic retrieval evaluates live signals instead of relying solely on precomputed relevance. This makes systems more responsive to task changes, recent behavior, and domain variation. The contrast can be represented structurally:
Table: Retrieval Models in Engines vs Ecosystems
| Model | Retrieval Type | Strength |
|---|---|---|
| Engines | Static index | Speed |
| Ecosystems | Dynamic, context-driven | Precision, personalization |
Dynamic pipelines enable the system to refine outputs as new information enters the interaction stream.
Feedback Loops and Ecosystem Learning
Intelligent discovery systems rely on feedback loops that continuously adjust model behavior. User interactions—corrections, refinements, confirmations, dwell time, and navigation patterns—serve as signals that update internal relevance models. These loops ensure that systems do not rely exclusively on initial assumptions.
Feedback operates at multiple levels. Retrieval agents update weighting strategies, interpretive models adjust embeddings, and ranking components refine confidence estimates. Ecosystems integrate these signals across layers, allowing contextual alignment to improve without full system retraining.
This recursive structure enables the system to evolve in real time as user needs and environments shift.

Multi-Agent Systems in the New Search Paradigm of Ecosystem-Driven Discovery
Multi-agent search systems redefine how discovery operates in environments where information, intent, and tasks change rapidly. Predictive discovery models now anticipate user needs before a query is issued, shifting emphasis toward proactive search systems that surface results through context alone. As passive discovery trends expand, ambient discovery systems embed retrieval directly into workflows, enabling information to appear without explicit navigation. These developments frame multi-agent discovery as the structural logic of ecosystem-driven search.
Agents as the New Crawlers
In ecosystem architectures, agents replace traditional crawlers by performing not only data collection but also interpretation and task reasoning. Each agent operates with a defined role—retrieval, validation, synthesis, ranking—and collaborates with others through contextual signals. This transforms discovery from a linear pipeline into an adaptive network.
Agents understand task goals instead of merely indexing content. Their design allows them to analyse instructions, follow intent trajectories, and apply domain-specific reasoning. Work on multi-agent retrieval frameworks demonstrates how specialized agents coordinate to refine relevance and resolve ambiguity across complex information environments.
Agents become functional decision-makers that shape the quality and direction of discovery.
Proactive vs Reactive Discovery
Discovery is moving from reactive retrieval to proactive prediction. Reactive systems wait for explicit queries. Proactive systems infer intent early and generate suggestions before the user asks. This shift is visible in platforms that produce anticipatory responses based on behavioral signals, task flows, and recent context.
Examples include proactive replies in Perplexity, where agents surface explanations and citations ahead of user refinement. Google SGE delivers contextual expansions triggered by partial queries or task patterns. ChatGPT provides multi-step suggestions inferred from the structure of the conversation. These mechanisms reveal how predictive discovery models treat search as an unfolding process rather than a moment.
Proactive discovery reduces cognitive load by aligning system output with evolving user goals.
Ambient Discovery as the New Default
Ambient discovery positions information as a background layer that responds to context instead of explicit intent. Systems observe task continuity, device transitions, and environmental cues to surface relevant material during activity rather than after a search request. This turns discovery into an integrated part of user interaction rather than a separate task.
In ambient systems, content appears in the right moment: a definition during reading, a reference during writing, or a recommendation during navigation. This aligns with passive discovery trends, where retrieval is woven into workflows without requiring user activation. The system continuously evaluates context to maintain alignment with ongoing tasks.
Ambient discovery becomes the default because it reduces friction and increases relevance across interactions.
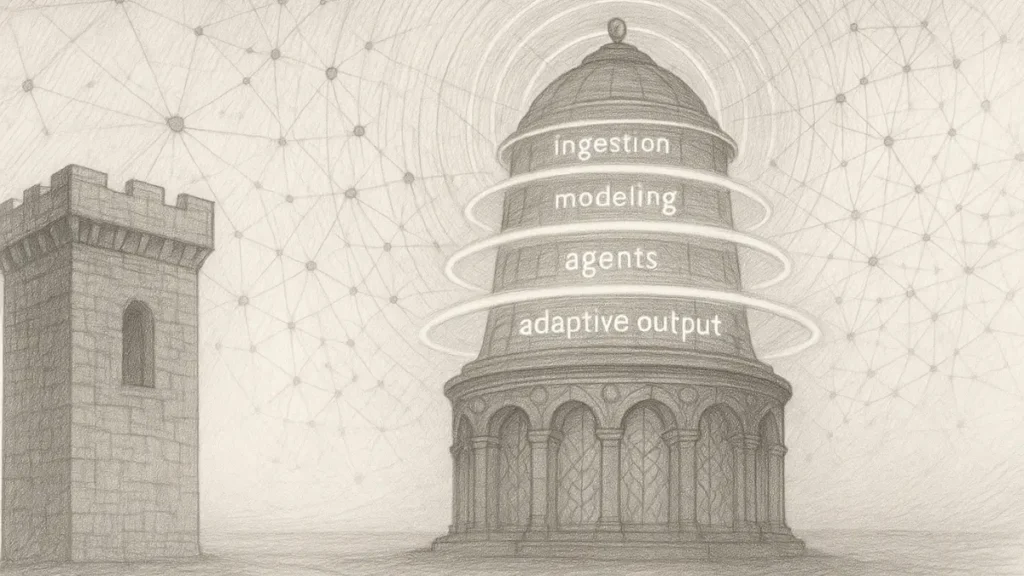
Architectural Comparison: Engines vs Ecosystems
The evolving search architecture reflects a shift from linear retrieval pipelines toward distributed, adaptive frameworks. Next-generation search models no longer rely on the stability of centralized indexing but instead operate through decentralized search concepts that integrate context at multiple stages. As new digital discovery models emerge, systems restructure information flow to support ecosystem-level reasoning. These changes define how engines and ecosystems differ structurally, operationally, and functionally.
Old Architecture (Engines)
Traditional engines operate through a fixed four-stage pipeline: Crawling → Index → Ranking → SERP. Crawling gathers documents, indexing structures them for fast lookup, and ranking applies relevance rules before producing a search results page. This architecture depends on global logic that governs the entire pipeline.
The model assumes stability: documents change slowly, intent is explicit, and ranking signals remain predictable. Any modification to relevance logic requires recalibrating the whole system. This makes engines effective for static tasks but insufficient for dynamic, context-rich environments.
The linear structure limits adaptability because each step is tightly coupled to the previous one.
New Architecture (Ecosystems)
Ecosystem-based systems replace linear pipelines with distributed, context-aware stages. Discovery occurs through the sequence Ingestion → Contextual Modeling → Agentic Evaluation → Adaptive Output. Ingestion processes raw signals, contextual modeling interprets meaning, agentic layers evaluate tasks, and adaptive output formats the result for the interaction channel.
These systems operate as interconnected networks rather than fixed hierarchies. Multiple agents contribute specialized reasoning while sharing contextual information. Insights from next-generation retrieval architectures show how ecosystem pipelines integrate semantic modeling with multi-agent evaluation to support flexible, real-time discovery.
The architecture evolves continuously as models learn from interaction patterns and task variations.
Why Architecture Determines Visibility
Visibility in ecosystem-driven search depends on compatibility with model-driven interpretation rather than keyword alignment. Engines reward isolated query matching, but ecosystems evaluate the structure, clarity, and factual grounding of content. Discovery relies on how well a page supports reasoning, extraction, and contextual linking.
Content must be written for models because model behavior defines which information becomes reusable across agents. Ecosystems extract entities, relationships, steps, and evidence, favoring pages with explicit logic, stable terminology, and structured hierarchy. Query-specific optimization loses relevance when discovery operates through contextual inference rather than explicit search terms.
Architecture determines visibility because the system can only surface what it can interpret.

The Cross-Platform Discovery Flow
The cross-platform discovery flow describes how information moves across systems, interfaces, and devices through shared context rather than isolated interactions. Contextual information systems increasingly interpret signals from multiple environments to build coherent user models. As multi-layer information ecosystems expand, they form smart discovery networks capable of transferring meaning across platforms. These connected discovery networks allow discovery to function as a continuous process rather than a set of separate retrieval actions.
Information Travels Across Systems
Information no longer resides within a single site or platform. Ecosystems route meaning from one agent to another, allowing discovery to follow the user rather than remain tied to specific interfaces. Each agent contributes partial interpretation—retrieval, classification, enrichment—which is then passed to downstream components for further analysis.
This movement reflects how content now operates beyond page boundaries. Systems draw from diverse sources, interpret signals in parallel, and merge outputs into unified contextual layers. Insights from linked data interaction principles illustrate how cross-platform structures support consistent interpretation by standardizing how entities and relationships are represented.
Information travels freely because ecosystems prioritize continuity over location.
Ecosystem-Wide Trust Signals
Trust emerges at the ecosystem level rather than at the page level. Systems evaluate content using signals that extend beyond individual documents and incorporate broader contextual evidence. These signals help agents determine whether information is stable, reliable, and suitable for reuse across tasks.
Key trust signals include:
- Consistency of terminology across related pages
- Clear entity definitions supported by external references
- Structured hierarchy that aligns with reasoning tasks
- Recency of information relative to the domain
- Source diversity across citations and examples
- Stability of factual claims over time
Table: Ecosystem Trust Indicators
| Trust Factor | Description | System Interpretation Role |
|---|---|---|
| Terminology Stability | Consistent use of concepts and definitions | Reduces ambiguity during retrieval |
| External Evidence | References to authoritative sources | Confirms factual grounding |
| Structural Clarity | Clear headings, lists, and logic steps | Improves extractability for agents |
| Temporal Relevance | Updated or validated information | Prioritizes freshness |
| Cross-Source Convergence | Alignment across multiple independent sources | Strengthens reliability scoring |
| Reasoning Compatibility | Explicit chains of logic | Supports multi-agent evaluation |
These factors enable systems to evaluate content not only in isolation but as part of a larger interpretive network.
Trust becomes an emergent property when multiple layers validate the same signals.
Content Discovery Evolution and Visibility Strategies
Content discovery evolution reflects how modern systems identify, interpret, and repurpose information across dynamic environments. A discovery-first content strategy prioritizes structure, reasoning, and clarity so systems can extract meaning without relying on direct queries. As new information discovery expands across interfaces, real-time information discovery becomes central to how content appears in responses, cards, and generated summaries. Ecosystem-based recommendation models strengthen this process by aligning retrieval with contextual signals rather than keyword matching.
How Content Gets Discovered Today
Discovery now occurs through multiple layers of interpretation rather than a single ranked list. Systems surface information in modular formats such as cards, structured snippets, agent-generated answers, and reasoning chains. Each format represents a transformation of underlying content into a context-specific unit optimized for interpretation.
Agents analyze page structure, semantic signals, and factual evidence to determine how information should appear. The decision depends on how well the content aligns with model reasoning tasks. Insights from real-time content recommendation frameworks demonstrate how modern systems evaluate content across multiple layers before selecting an output.
Discovery therefore reflects the system’s ability to map structured meaning to user intent in real time.
Discovery-First Strategy vs Search-First Strategy
A search-first approach optimizes content for engines that rely on ranking signals and keyword relevance. A discovery-first approach optimizes content for ecosystem reuse, where information must be interpretable, extractable, and logically encoded. The difference becomes clear when examining how systems produce outputs:
Table: Search-First vs Discovery-First Strategies
| Strategy | Optimized For | Output Type |
|---|---|---|
| Search-first | Engines | Rankings |
| Discovery-first | Ecosystems | Reuse in answers |
Discovery-first formats allow systems to generate explanations, summaries, and contextualized outputs that align with multi-agent reasoning.
A discovery-first strategy supports visibility by enabling content to integrate directly into intelligent outputs.
Types of Content That Win in Ecosystems
Ecosystems elevate content that aligns with reasoning-based interpretation. Three categories consistently perform well:
- Reasoning-ready content: pages that present logic, steps, relationships, and definitions in a format models can reproduce.
- Highly structured content: clear headings, lists, tables, diagrams, and stable conceptual boundaries that help agents extract meaning.
- Factual content: verified claims, data, external citations, and evidence that support high-confidence synthesis across agents.
These content types strengthen a page’s suitability for reuse across discovery flows. They mirror the attributes systems require to interpret information with precision.
Content gains visibility when it can be transformed into structured, explainable outputs.

Future of Search: Predictive, Proactive, Ecosystem-Driven
The future of online discovery is shifting toward systems that anticipate needs instead of responding to explicit queries. The future of search systems depends on architectures capable of interpreting early contextual cues and shaping outputs before users request information. This AI-driven discovery shift reflects a broader transition toward predictive discovery models that evaluate reasoning, context, and behavioral signals in real time. As proactive search systems mature, they transform discovery into a continuous, ecosystem-driven process.
Search Without Queries
Search is evolving into a model where information appears without a direct query. Early-stage signals—such as personalization, task history, and environmental context—allow systems to infer intent before users articulate it. These signals enable engines to anticipate needs by analyzing patterns across recent interactions and tasks.
Predictive discovery relies on interpreting subtle cues: time of day, device transitions, writing context, or previous queries. Research on predictive information access models shows how systems monitor these signals to estimate upcoming actions. As a result, discovery becomes an embedded layer that adapts to the user’s information trajectory.
This transition reduces friction by transforming retrieval into a background process.
Agents as Personal Information Layers
In the next stage of evolution, agents function as personal information layers that embed discovery directly into daily workflows. These agents track long-term preferences, interpret evolving goals, and proactively refine suggestions. The result is a form of “invisible search,” where information appears naturally during reading, writing, planning, or decision-making.
Personal agents integrate signals across multiple sources—documents, apps, conversations—and transform them into task-aware insights. Their role is not to retrieve pages but to construct contextually aligned explanations, summaries, and suggestions. Over time, these agents become persistent components of the user’s information environment.
Discovery becomes ambient because personal agents continuously reason about what the user is trying to achieve.
What the Next 5 Years Look Like
Over the next five years, discovery will evolve toward personal information spheres powered by multi-layered ecosystems. Users will interact with systems that merge retrieval, reasoning, and context modeling into unified pipelines. These pipelines will support multi-agent decision-making, where specialized agents interpret tasks and collaborate to produce cohesive outputs.
Content will increasingly move through cross-platform ecosystems that synchronize discoveries across devices and applications. Personalized layers will refine outputs with task continuity, creating consistent informational support. Ecosystems will adapt in real time as behavioral patterns shift, forming high-resolution models of user intent.
Search will become predictive, proactive, and deeply integrated into everyday activity.
Checklist:
- Does the page define its core concepts with precise terminology?
- Are sections organized with stable H2–H4 boundaries?
- Does each paragraph express one clear reasoning unit?
- Are examples used to reinforce abstract concepts?
- Is ambiguity eliminated through consistent transitions and local definitions?
- Does the structure support step-by-step AI interpretation?

Embracing the New Search Paradigm
The new search paradigm redefines how information is discovered, interpreted, and reused across digital environments. Ecosystem-centered search replaces linear retrieval with multi-layer reasoning that reflects real user behavior. As discovery-first content strategy becomes the dominant model, visibility depends on how effectively content supports interpretation rather than how well it matches isolated queries. This shift requires creators to design information for machines that read context, not keywords.
Engines Are Ending — Ecosystems Are Beginning
Search engines built on centralized indexing and static ranking are losing relevance as ecosystems take precedence. Ecosystems evaluate meaning through distributed agents that interpret structure, evidence, and context in parallel. This establishes a new standard of visibility based on clarity, reasoning compatibility, and factual grounding.
Ecosystems reward content that expresses logic, communicates relationships, and provides extractable structure.
What Creators Must Adapt to Immediately
Creators must adjust workflows to align with ecosystem-driven discovery. Several actions are essential:
- Present information in clear hierarchical structures with stable terminology.
- Use headings, lists, tables, and definitions that reflect conceptual boundaries.
- Write in short, declarative sentences that models can extract cleanly.
- Provide factual grounding and evidence for claims to support multi-agent verification.
- Maintain consistency across related pages to strengthen semantic cohesion.
- Prioritize reasoning-ready formats that reveal how ideas connect.
- Build content for reuse in answers, summaries, cards, and contextual outputs.
These adaptations ensure that content remains interpretable and reusable across ecosystem pipelines.
The Future Belongs to Ecosystems, Not Engines
Ecosystems will dominate discovery because they reflect how humans interact with information—continuously, contextually, and across devices. They reward structure, clarity, and semantic coherence, not keyword density. As search becomes predictive and proactive, content must support model reasoning at every stage.
The shift to ecosystems marks a long-term transition: creators who embrace discovery-first logic will define the standards of visibility in the coming era.
Interpretive Alignment with Ecosystem-Based Search
- Concept boundary resolution. Search systems interpret content through clearly bounded ideas, where each section represents a distinct semantic scope without overlap.
- Structure-driven extractability. Headings, lists, tables, and micro-blocks act as segmentation signals that allow logic to be extracted and recomposed across discovery environments.
- Explicit semantic grounding. Definitions, relationships, and factual references stabilize meaning for multi-agent reasoning and contextual synthesis.
- Interconnected meaning pathways. Semantic links between related concepts enable systems to follow continuity across documents rather than isolated pages.
- Cross-interface interpretability. Content that remains coherent across summaries, answers, and reasoning views indicates alignment with ecosystem-based discovery models.
This alignment explains how the new search paradigm interprets content as part of an interconnected semantic ecosystem, where structure and meaning guide visibility independently of procedural optimization.
FAQ: The New Search Paradigm
What is the new search paradigm?
The new search paradigm shifts discovery from centralized engines to distributed ecosystems that interpret meaning through context, semantic signals, and multi-agent reasoning.
How do ecosystems differ from traditional search engines?
Engines rely on static indexing and ranking logic, while ecosystems use distributed agents that evaluate structure, intent, and context dynamically across multiple layers.
Why are ecosystems more effective in modern information environments?
Ecosystems adapt to continuous context changes and multimodal interactions, allowing them to interpret meaning more precisely than linear retrieval systems.
How do ecosystem-based systems choose which content to display?
They evaluate semantic clarity, factual reliability, structure, and contextual alignment, selecting content that is easiest for agents to reuse in reasoning and summaries.
Why is structure critical in ecosystem-driven discovery?
Clear hierarchy, lists, definitions, and tables help multi-agent systems extract meaning efficiently and reduce ambiguity during interpretation.
What makes content visible in ecosystem-level search?
Visibility depends on reasoning compatibility, semantic stability, and clarity—not keyword density. Systems reward information that can be reused across tasks.
What role does context play in ecosystem-based search?
Context shapes how systems interpret user intent across tasks, devices, and interactions, enabling continuous discovery instead of isolated queries.
How do multi-agent systems support discovery?
Each agent performs specialized reasoning—retrieval, validation, synthesis, ranking—and contributes its output to a shared context layer.
Why do ecosystems outperform engines during rapid change?
Ecosystems update interpretation in real time and isolate errors at the agent level, avoiding failures that propagate through linear pipelines.
How can creators adapt to the new search paradigm?
Creators must prioritize structured reasoning, factual grounding, stable terminology, and semantic clarity to support multi-agent interpretation.
Glossary: Key Terms in the New Search Paradigm
This glossary defines core terminology used throughout the article to support consistent interpretation by both readers and AI-driven discovery systems.
Search Ecosystem
A distributed discovery environment where multiple agents interpret context, meaning, and relevance across interconnected layers instead of relying on a single centralized engine.
Contextual Discovery
A discovery process where systems infer intent and meaning from surrounding signals rather than explicit queries, enabling continuous information flow across tasks and devices.
Multi-Agent Reasoning
A collaborative evaluation method where specialized agents perform retrieval, synthesis, validation, or ranking, contributing to shared context through parallel reasoning.
Layered Intent
A model of user intent based on accumulated behavior signals, context transitions, and micro-actions, allowing systems to interpret evolving goals over time.
Dynamic Retrieval
A retrieval method that evaluates relevance in real time based on context, signals, and system state instead of relying solely on static index scores.
Ecosystem Trust Signals
Indicators used by discovery systems—such as terminology stability, structural clarity, factual grounding, and cross-source convergence—to assess whether content is suitable for reuse.

Author Sergey Kuchinskiy
Founder of PostUpgrade. Researcher in Generative Engine Optimization (GEO), semantic structuring, and machine reasoning systems. Focuses on AI-readable content architecture, computational interpretation, and scalable knowledge retrieval. Author of 200+ analytical publications on generative visibility, semantic mapping, and AI-first information design.
Verified Expertise
- Generative Engine Optimization (GEO)
- AI Content Engineering & Semantic Structuring
- Computational Linguistics & Machine Reasoning
- Large-Scale Content Architecture
Research Focus
AI Search · Generative Visibility · Semantic Mapping · Machine Sentence Design · Reasoning Stability · Knowledge Extraction Models
Academic Contributions
- 200+ analytical research publications
- AI-first page architecture methodologies
- Semantic Frameworks for Machine Interpretation (SFMI)
- Generative Visibility Standards 2024–2025
Citation Metrics
AI-model reuse rate (GEO-Score): 92/100 · Cross-model consistency: 87% · Reasoning chain stability: 91%
Researcher ID: PU-ORCID-7421-9912
View all publications →Connect on LinkedIn →